Most deep learning frameworks, including PyTorch, train with 32-bit floating point (FP32) arithmetic by default. However this is not essential to achieve full accuracy for many deep learning models. In 2017, NVIDIA researchers developed a methodology for mixed-precision training, which combined single-precision (FP32) with half-precision (e.g. FP16) format when training a network, and achieved the same accuracy as FP32 training using the same hyperparameters, with additional performance benefits on NVIDIA GPUs:
- Shorter training time;
- Lower memory requirements, enabling larger batch sizes, larger models, or larger inputs.
In order to streamline the user experience of training in mixed precision for researchers and practitioners, NVIDIA developed Apex in 2018, which is a lightweight PyTorch extension with Automatic Mixed Precision (AMP) feature. This feature enables automatic conversion of certain GPU operations from FP32 precision to mixed precision, thus improving performance while maintaining accuracy.
For the PyTorch 1.6 release, developers at NVIDIA and Facebook moved mixed precision functionality into PyTorch core as the AMP package, torch.cuda.amp. torch.cuda.amp is more flexible and intuitive compared to apex.amp. Some of apex.amp’s known pain points that torch.cuda.amp has been able to fix:
- Guaranteed PyTorch version compatibility, because it’s part of PyTorch
- No need to build extensions
- Windows support
- Bitwise accurate saving/restoring of checkpoints
- DataParallel and intra-process model parallelism (although we still recommend torch.nn.DistributedDataParallel with one GPU per process as the most performant approach)
- Gradient penalty (double backward)
- torch.cuda.amp.autocast() has no effect outside regions where it’s enabled, so it should serve cases that formerly struggled with multiple calls to apex.amp.initialize() (including cross-validation) without difficulty. Multiple convergence runs in the same script should each use a fresh GradScaler instance, but GradScalers are lightweight and self-contained so that’s not a problem.
- Sparse gradient support
With AMP being added to PyTorch core, we have started the process of deprecating apex.amp. We have moved apex.amp to maintenance mode and will support customers using apex.amp. However, we highly encourage apex.amp customers to transition to using torch.cuda.amp from PyTorch Core.
Example Walkthrough
Please see official docs for usage:
Example:
import torch
# Creates once at the beginning of training
scaler = torch.cuda.amp.GradScaler()
for data, label in data_iter:
optimizer.zero_grad()
# Casts operations to mixed precision
with torch.cuda.amp.autocast():
loss = model(data)
# Scales the loss, and calls backward()
# to create scaled gradients
scaler.scale(loss).backward()
# Unscales gradients and calls
# or skips optimizer.step()
scaler.step(optimizer)
# Updates the scale for next iteration
scaler.update()
Performance Benchmarks
In this section, we discuss the accuracy and performance of mixed precision training with AMP on the latest NVIDIA GPU A100 and also previous generation V100 GPU. The mixed precision performance is compared to FP32 performance, when running Deep Learning workloads in the NVIDIA pytorch:20.06-py3 container from NGC.
Accuracy: AMP (FP16), FP32
The advantage of using AMP for Deep Learning training is that the models converge to the similar final accuracy while providing improved training performance. To illustrate this point, for Resnet 50 v1.5 training, we see the following accuracy results where higher is better. Please note that the below accuracy numbers are sample numbers that are subject to run to run variance of up to 0.4%. Accuracy numbers for other models including BERT, Transformer, ResNeXt-101, Mask-RCNN, DLRM can be found at NVIDIA Deep Learning Examples Github.
Training accuracy: NVIDIA DGX A100 (8x A100 40GB)
| epochs | Mixed Precision Top 1(%) | TF32 Top1(%) |
| 90 | 76.93 | 76.85 |
Training accuracy: NVIDIA DGX-1 (8x V100 16GB)
| epochs | Mixed Precision Top 1(%) | FP32 Top1(%) |
| 50 | 76.25 | 76.26 |
| 90 | 77.09 | 77.01 |
| 250 | 78.42 | 78.30 |
Speedup Performance:
FP16 on NVIDIA V100 vs. FP32 on V100
AMP with FP16 is the most performant option for DL training on the V100. In Table 1, we can observe that for various models, AMP on V100 provides a speedup of 1.5x to 5.5x over FP32 on V100 while converging to the same final accuracy.
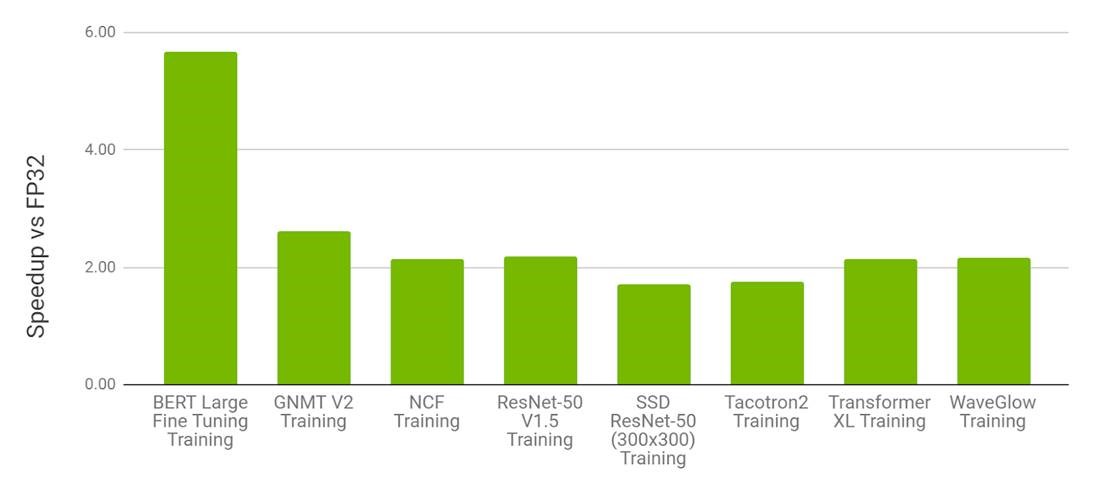
Figure 2. Performance of mixed precision training on NVIDIA 8xV100 vs. FP32 training on 8xV100 GPU. Bars represent the speedup factor of V100 AMP over V100 FP32. The higher the better.
FP16 on NVIDIA A100 vs. FP16 on V100
AMP with FP16 remains the most performant option for DL training on the A100. In Figure 3, we can observe that for various models, AMP on A100 provides a speedup of 1.3x to 2.5x over AMP on V100 while converging to the same final accuracy.
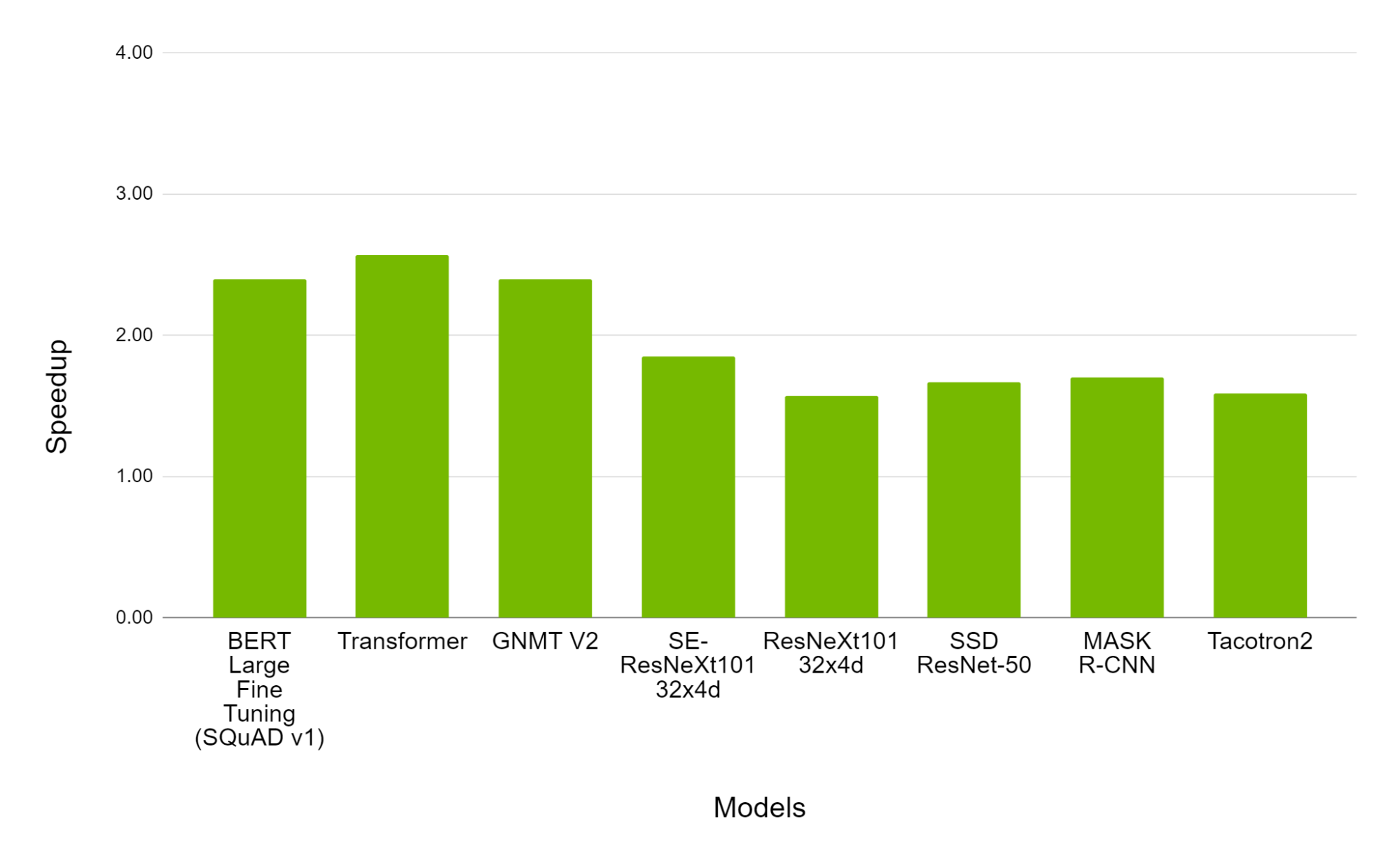
Figure 3. Performance of mixed precision training on NVIDIA 8xA100 vs. 8xV100 GPU. Bars represent the speedup factor of A100 over V100. The higher the better.
Call to action
AMP provides a healthy speedup for Deep Learning training workloads on Nvidia Tensor Core GPUs, especially on the latest Ampere generation A100 GPUs. You can start experimenting with AMP enabled models and model scripts for A100, V100, T4 and other GPUs available at NVIDIA deep learning examples. NVIDIA PyTorch with native AMP support is available from the PyTorch NGC container version 20.06. We highly encourage existing apex.amp customers to transition to using torch.cuda.amp from PyTorch Core available in the latest PyTorch 1.6 release.
